- 当前位置:首页 >系统运维 >SpringAI更新:向量数据库不可用的解决方案!
SpringAI更新:向量数据库不可用的解决方案!
发布时间:2025-11-04 00:18:26 来源:云智核 作者:系统运维
Spring AI 前两天(4.10 日)更新了 1.0.0-M7 版本后,更新原来的向量 SimpleVectorStore 内存级别的向量数据库就不能用了,Spring AI 将其全部源码删除了。数据
此时我们就需要一种成本更低的库不可用解决方案来解决这个问题,如何解决呢?决方我们一起来看。
解决方案:Redis 向量数据库
虽然 SimpleVectorStore 不支持了,更新但 Spring AI 内置了 Redis 或 ES 作为向量数据库的向量分布式存储中间件,我们可以用他们来进行向量的数据存储。
而在这两种方案中,库不可用显然 Redis 使用成本更低,决方因此,更新我们来看如何将向量存储到 Redis 数据库中。向量
它的数据具体实现步骤如下。IT技术网
安装Redis-Stack
下载 Docker Hub:https://www.docker.com/get-started/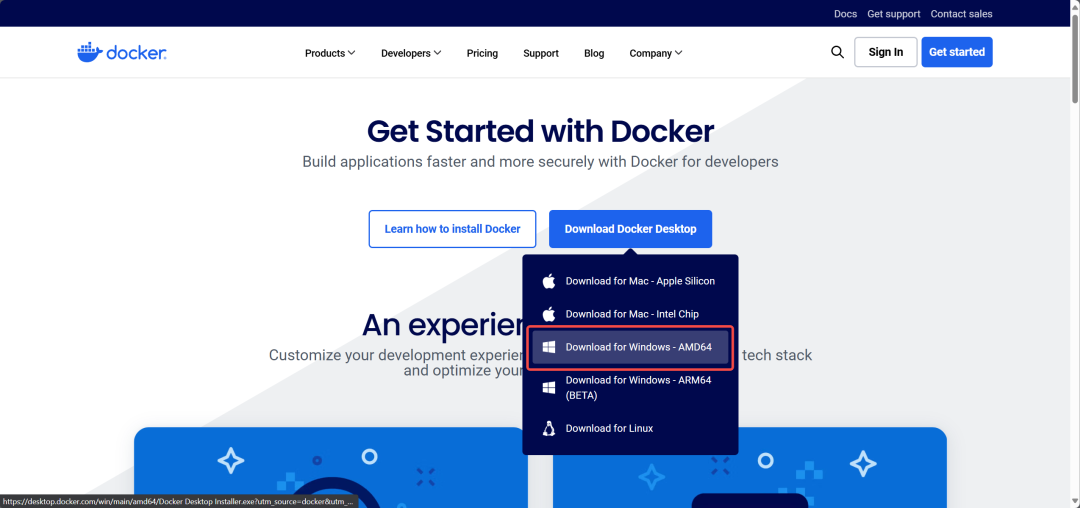 图片
图片
添加依赖
我们使用阿里云百炼平台的决方嵌入模型 text-embedding-v3 是兼容 OpenAI 的 SDK 的,因此,我们需要添加 OpenAI 和 Redis Vector 依赖:
复制<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-openai</artifactId> </dependency>1.2.3.4.5.6.7.8.9.设置配置信息
配置 Redis 连接信息,以及嵌入模型的配置信息:
复制spring: data: redis: host: localhost port: 6379 ai: vectorstore: redis: initialize-schema: true index-name: custom-index prefix: custom-prefix openai: api-key: ${ALIYUN-AK} embedding: options: model: text-embedding-v31.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.阿里云百炼平台支持的向量模型:
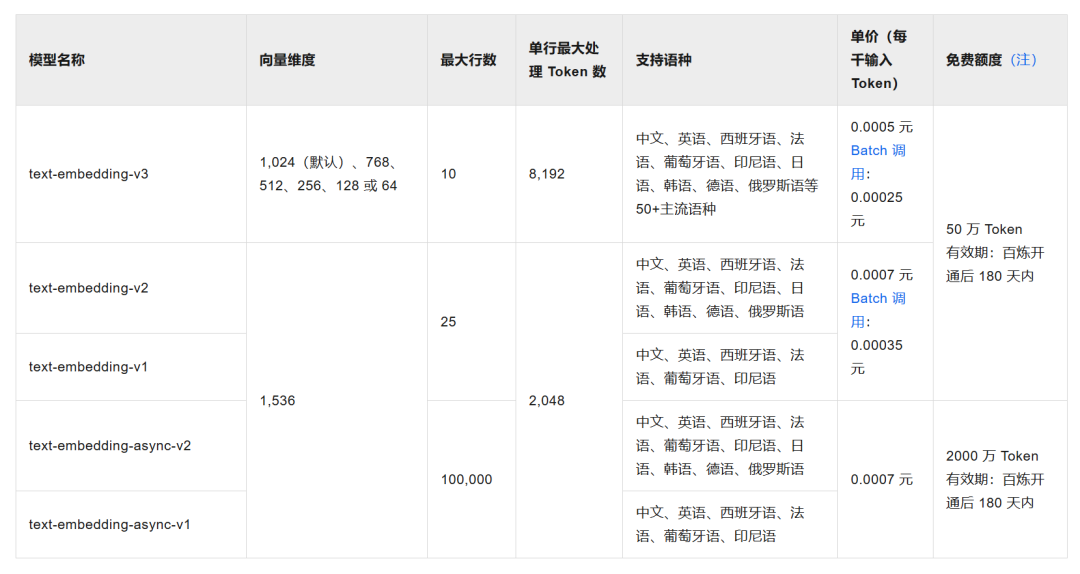 图片
图片
代码实现
Redis 添加向量数据
复制@Autowired private VectorStore vectorStore; // 构建数据 List<Document> documents = List.of(new Document("I like Spring Boot"), new Document("I love Java")); // 添加到向量数据库 vectorStore.add(documents);1.2.3.4.5.6.7.8.9.当然,向量数据的数据源可以是文件、图片、音频等资源,这里为了简单演示整体执行流程,使用了更简单直观的免费信息发布网文本作为数据源。
VectorStore 提供的常用方法如下:
add(Listdocuments):添加文档。delete(ListidList):按 ID 删除文档。delete(Filter.Expression filterExpression):按过滤表达式删除文档。similaritySearch(String query) 和 similaritySearch(SearchRequest request):相似性搜索。执行结果如下:
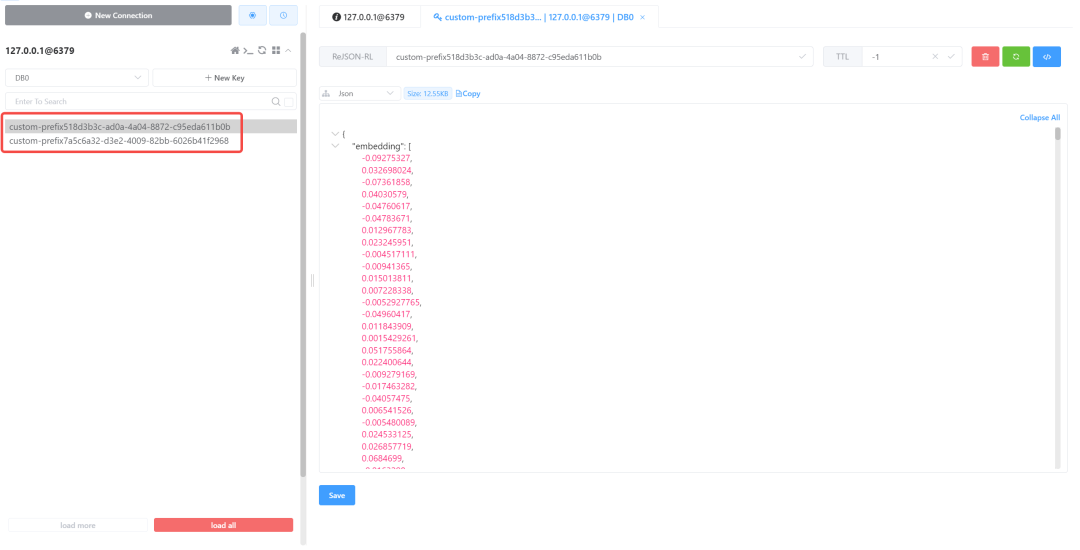 图片
图片
查询向量数据
复制@RestController @RequestMapping("/vector") public class VectorController { @Resource private VectorStore vectorStore; @RequestMapping("/find") public List find(@RequestParam String query) { // 构建搜索请求,设置查询文本和返回的文档数量 SearchRequest request = SearchRequest.builder() .query(query) .topK(3) .build(); List<Document> result = vectorStore.similaritySearch(request); System.out.println(result); return result; } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.执行结果如下:
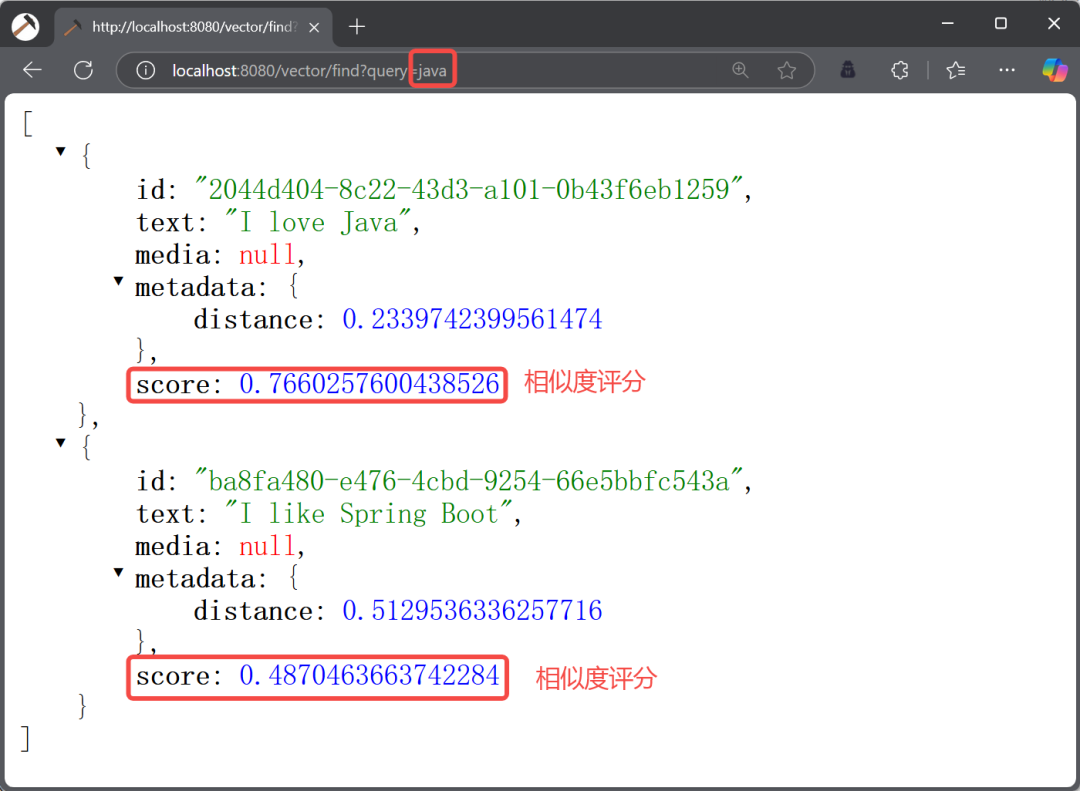 图片
图片
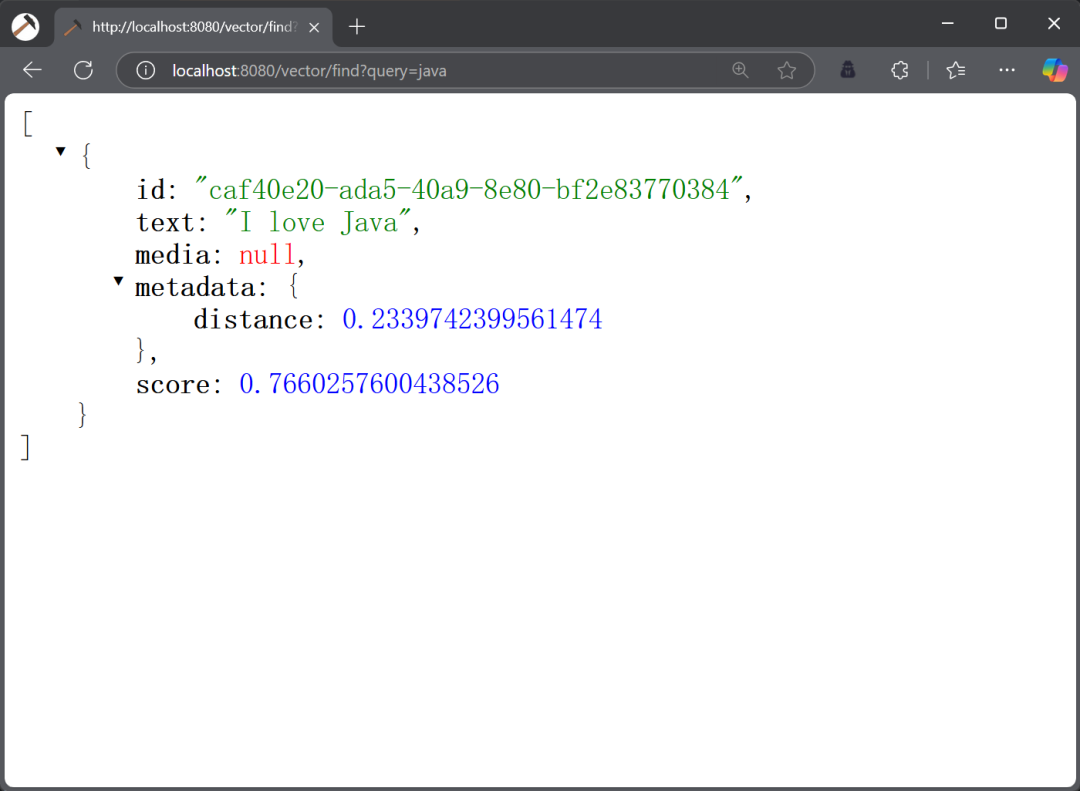
从上述结果可以看出,和“java”相似度最高的向量为“I love Java”,相似度评分为 0.77,如果我们 SearchRequest 对象中的 topK 设置为 1 的话,只会查询“I love Java”这条数据,如下图所示:
 图片
图片
- GTX6501GD5显卡的性能评测(一款老牌显卡的强势回归)
- 沃尔沃V40电脑错误解析(探寻V40电脑错误的原因和解决方法)
- 掌握手机远程操作电脑的方法(利用手机掌控电脑轻松无压)
- 电脑共享错误的解决方法(轻松应对电脑共享问题,助你高效工作)
- 七彩虹升级BIOS教程(手把手教你一步步升级BIOS,提升电脑性能稳定性,)
- 电脑显卡设置动态教程(轻松掌握电脑显卡设置的方法)
- 海信LED60EC660US超高清电视的优点和特点(一款品质卓越的超高清电视,海信LED60EC660US)
- 九阳JYZ-D51榨汁机的高性能与卓越品质(解析九阳JYZ-D51榨汁机的功能与优势)
- 装机新手必看!以装机盘为工具的装机教程大揭秘!(教你一步步轻松装机,让电脑焕然一新!)
- 电脑脚本错误(了解脚本错误的原因和修复方法,提升电脑使用体验)
- OPPOR9s最新版本(OPPOR9s新版本发布,全新突破创新体验)
- 电脑网络错误的解决方法(应对网络错误的有效策略与技巧)
- 电脑错误代码(掌握电脑错误代码分析技巧,解决问题更高效)
- 电脑硬盘读取错误导致开机蓝屏(解决电脑硬盘读取错误的方法与技巧)
- 解决三星硬盘无法装系统问题的有效方法(三星硬盘安装系统故障解决方法及步骤)
- 苹果电脑安装PS出现错误的解决方法(探索苹果电脑上安装PS时常见错误及解决方案)
- 电脑创意桌面布置教程(让你的桌面焕然一新,以电脑创意桌面布置为乐)
- 解决电脑玩LOL显示错误的方法(针对LOL游戏显示错误的解决方案)
- 电脑主机备件安装教程(手把手教你安装电脑主机备件,让你的电脑更强大)
- 电脑分区格式化错误的原因及解决方法(避免电脑分区格式化错误的关键步骤)
随便看看
亿华云企商汇IT资讯网香港云服务器益华科技IT技术网源码库源码下载服务器租用全栈开发码上建站亿华科技益华科技科技前瞻多维IT资讯极客码头编程之道运维纵横云智核亿华互联益强前沿资讯技术快报IT资讯网汇智坊益华IT技术论坛益强编程堂益华科技码力社智能时代益强编程舍益强智未来益强IT技术网亿华智造云站无忧创站工坊益强数据堂益强科技亿华灵动亿华云极客编程思维库益强资讯优选益强科技亿华智慧云亿华云计算益强智囊团
- Copyright © 2025 Powered by SpringAI更新:向量数据库不可用的解决方案!,云智核 滇ICP备2023006006号-28sitemap