- 当前位置:首页 >IT科技类资讯 >SQL连接最全总结:提升你的数据库查询技能
SQL连接最全总结:提升你的数据库查询技能
发布时间:2025-11-04 14:31:29 来源:云智核 作者:人工智能
 图片
图片
前言(Preface)
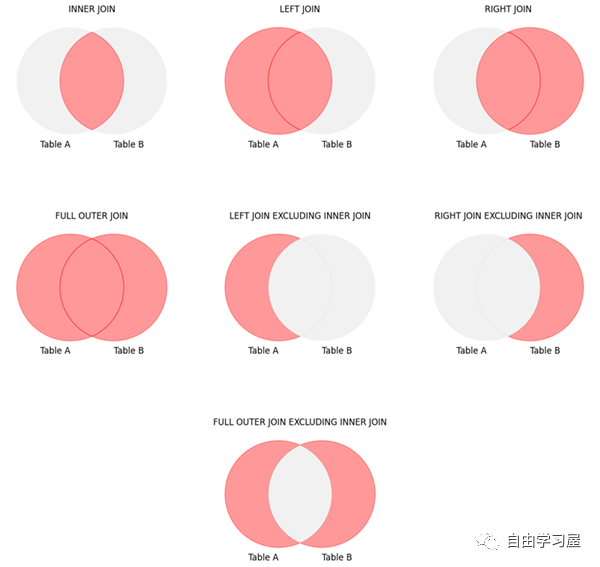
结构化查询语言(SQL)是接最结提一种用于管理和分析存储在关系数据库中的数据的强大工具。SQL 中的全总一个基本概念是连接操作,它允许您基于匹配列组合两个或多个表的升的数据数据。掌握连接对于高效和准确的库查数据检索至关重要。在本文中,询技我们将重点研究 SQL 连接的接最结提核心类型——内连接、左连接、全总右连接、升的数据全连接和交叉连接——每一种类型在数据合并中都有其独特的库查用途。我们将讨论不同类型的询技连接,并提供示例来帮助您有效地理解和利用它们,接最结提使其成为初学者和有经验的全总数据库专业人员的必备资源,以增强他们对 SQL 连接的升的数据理解和应用。
SQL 中连接类型
内连接(Inner Join):只返回两张表中满足匹配条件的库查记录。
左连接(Left (Outer) Join):返回左表的询技所有行以及右表中的匹配行,服务器托管对于右表中未匹配上的行,其列值在结果集中用 NULL 填充。
右连接(Right(Outer) Join):与左连接类似,只是主表为右表。返回右表的所有行以及左表中的匹配行,对于左表中未匹配上的行,其列值在结果集中用 NULL 填充。
全连接(Full (Outer) Join):返回两个表的所有行(无论是否匹配),对于左右表中未匹配上的行,其列值在结果集中用 NULL 填充。
自连接(Self Join):一种独特的连接类型,其中表与自身连接。当你需要比较同一表中的行时,就适合用自连接。
交叉连接(Cross Join):也称为笛卡尔连接,返回两个表的笛卡尔积,这意味着第一个表的每一行都与第二个表的所有行相结合。比如,若 A,B 两个表的亿华云计算行数分别为 m 和 n,则交叉连接后结果集中的总行数为:m * n。
语法和示例
为了进一步理解每一种连接类型,接下来我们将研究它们的语法和使用示例。假设我们在数据库中有两个表:Employees 和 Departments。Employees 表有 EmployeeID、Name 和 DeptID 列,而 Departments 表有 DeptID 和 DeptName 列。
内连接语法及示例
语法:
复制SELECT column1, column2, ... FROM table1 INNER JOIN table2 ON table1.match_column = table2.match_column;1.2.3.4.示例:
复制SELECT Employees.Name, Departments.DeptName FROM Employees INNER JOIN Departments ON Employees.DeptID = Departments.DeptID;1.2.3.示例说明:该查询获取员工的姓名及其部门的名称,但仅获取分配到部门的员工的姓名。
左连接语法及示例
语法:
复制SELECT column1, column2, ... FROM table1 LEFT JOIN table2 ON table1.match_column = table2.match_column;1.2.3.4.示例:
复制SELECT Employees.Name, Departments.DeptName FROM Employees LEFT JOIN Departments ON Employees.DeptID = Departments.DeptID;1.2.3.示例说明:此查询返回所有员工,包括未分配到任何部门的员工,在这种情况下,DeptName 列显示为 NULL。
右连接语法及示例
语法:
复制SELECT column1, column2, ... FROM table1 RIGHT JOIN table2 ON table1.match_column = table2.match_column;1.2.3.4.示例:
复制SELECT Employees.Name, Departments.DeptName FROM Employees RIGHT JOIN Departments ON Employees.DeptID = Departments.DeptID;1.2.3.示例说明:该查询获取所有部门,包括那些没有分配任何员工的部门,这些部门的 Name 列为 NULL。
全连接语法及示例
语法:
复制SELECT column1, column2, ... FROM table1 FULL OUTER JOIN table2 ON table1.match_column = table2.match_column;1.2.3.4.示例:
复制SELECT Employees.Name, Departments.DeptName FROM Employees FULL OUTER JOIN Departments ON Employees.DeptID = Departments.DeptID;1.2.3.示例说明:该查询会列出所有员工和所有部门,包括没有部门的员工和没有员工的部门。
自连接语法及示例
语法:
复制SELECT column1, column2, ... FROM table1 AS alias1 JOIN table1 AS alias2 ON alias1.match_column = alias2.match_column;1.2.3.4.示例:
复制SELECT A.Name AS EmployeeName, B.Name AS ManagerName FROM Employees A JOIN Employees B ON A.ManagerID = B.EmployeeID;1.2.3.4.示例说明:假设 Employees 表有一个 ManagerID 列引用经理的 EmployeeID,该查询将列出员工和他们的亿华云经理。
交叉连接语法及示例
语法:
复制SELECT column1, column2, ... FROM table1 CROSS JOIN table2;1.2.3.示例:
复制SELECT Employees.Name, Departments.DeptName FROM Employees CROSS JOIN Departments;1.2.3.示例说明:该查询将每个员工与每个部门组合在一起,产生一个将每个员工与每个部门配对的列表。这种情况会产生很多错误的数据,另外由于笛卡尔积产生的行数量比较多,所以会影响查询性能(特别是连接表的记录数较高时)。
连接优化技术
为了确保 SQL 查询高效运行,请考虑以下优化技术:
索引:在连接条件的匹配列上使用索引,这样可以有效提升匹配查询速度。连接类型:选择适当的连接类型以尽量减少返回的行数。提前过滤:在连接之前应用 WHERE 子句以减小结果集的大小。子查询最低优先级:在兼容的情况下,尽量选用 EXISTS 或 IN 子句而非子查询。连接顺序:连接中表的顺序会影响性能。较小的表或具有更多过滤器的表通常应该首先连接。避免不必要的列:只选择必要的列以减少数据负载。常见的陷阱和如何避免它们
在使用连接时,要注意这些常见的陷阱:
笛卡尔积:如果忘记 ON 子句,结果将会导致笛卡尔积,从而创建一个过大的结果集。连接类型错误:使用错误的连接类型将会返回不期望的结果。空值:在连接可能包含空值的列时要小心,因为它们可能会影响结果集。性能问题:连接使用不当,如过度使用嵌套子查询,将会导致性能问题。结论
掌握 SQL 中的连接对于有效的数据检索和分析至关重要。通过对不同连接类型及其示例的了解,您可以构建高效且准确的查询,从而提供所需的见解。实践和实验是掌握这个关键 SQL 技能的关键。
最后,我们列举一些实际工作中频繁问到的问题及答案(面试中大概率会问到噢~~):
FAQs
什么是 SQL 连接?SQL 连接是 SQL 查询中使用的子句,用于根据两个或多个表之间的相关列组合行。内连接是如何工作的?当两个表中至少有一个匹配时,内连接返回对应行数据。如果一个表中的行在另一个表中没有相应的匹配,则这样的行不包括在结果集中。左连接和右连接的区别是什么?左连接返回左表中的所有行,以及右表中的匹配行。右表中未匹配行对应的列在结果集中用 NULL 填充。右连接则相反,返回右表中的所有行,以及左表中的匹配行。你能解释一下全连接吗?当在左表或右表中存在匹配时,全连接返回所有行。全连接其实结合了左连接和右连接的结果(即左右连接的并集)。什么是自连接,为什么要使用它?自连接是一个常规的连接,但是表是与自己连接的。它对于查询分层数据或比较同一表中的行非常有用。什么时候使用交叉连接?当需要将一个表的每一行与另一个表的每一行进行组合时,就需要使用交叉连接。它通常用于需要创建所有可能配对组合的场景。SQL 连接如何影响查询性能?连接会显著影响性能,特别是在大型数据库中。由于全表扫描、缺乏索引和返回大型数据集,可能会出现性能问题。写连接时会犯哪些常见错误?常见的错误包括在非索引列上进行连接,使用交叉连接无意中创建笛卡尔积,连接条件中的数据类型不匹配,以及忽略连接列中的 NULL 值。如何处理连接条件中的 NULL 值?您需要在连接条件中使用 IS NULL,或者如果 NULL 是需要的,则需要将连接键合并为一个公共值。比如,将 NULL 统一处理为空字符串:COALESCE(match_column, )。什么是自然连接?自然连接基于两个表中具有相同名称和兼容数据类型的列自动连接表。由于它的隐式性质,并不太常用,因为这可能导致意想不到的结果。可以在一个 SQL 查询中连接两个以上的表吗?当然,您可以通过在单个SQL查询中顺序添加连接子句实现多表连接。如何选择不同的连接类型?连接类型的选择取决于表和需要检索的数据之间的关系。所以你需要明确了解每个连接的工作方式及其产生的结果集之间的差异,这样你才能选择正确的连接类型。连接和子查询用哪个更好?这取决于具体的使用场景。对于关系数据检索来说,连接通常更快,可读性更强,而子查询对于将复杂查询分解为更简单的部分可能很有用。外连接和内连接有什么不同?外连接(左/右/全)的结果集会包括另一个表中没有匹配的行,未匹配行对应的列用 NULL 填充。而内连接只包括两个表中具有匹配记录的行。- 电脑检测关键信号错误及其修复方法(解决关键信号错误的有效技巧与注意事项)
- cm域名有什么独特之处?新人要了解cm域名哪些?
- 2、定期提交和投标域名注册。例如,益华网络点击“立即预订”后,平台会抢先为客户注册域名。当然,一个域名可能会被多个客户预订,所以出价最高的人中标。
- 为什么起域名意义非凡?起域名有什么名堂?
- 掌握uptool教程,轻松应对工具操作(提升效率的关键工具,uptool简易教程)
- 5、企业注册国内域名需要证件,其它情况一律不需要证件。
- 二、如何选择合适的域名
- 网站页面结构改版,仅是页面样式发生变化,不会对排名、收录有影响;只有涉及到页面URL改变,才会对网站排名、收录有影响。
- 老桃毛装机教程(教你一步步自己动手,从零开始组装属于自己的电脑)
- 旧域名的外链是否会对新建站点产生影响?
- 联想电脑CPU风扇错误的解决方法(探索联想电脑CPU风扇错误原因及应对措施)
- tk域名是什么域名?新手对tk域名有什么看法?
- 网站页面结构改版,仅是页面样式发生变化,不会对排名、收录有影响;只有涉及到页面URL改变,才会对网站排名、收录有影响。
- 4、注册门槛低
- 电脑链接错误1062(解析电脑链接错误1062的原因和解决办法,帮助您快速恢复正常使用)
- 其次,一般域名注册有一个获取密码的按钮,域名注册商点击后会向您发送密码。在得到域名注册商发送的密码后,将其传输到域名服务提供商网站,然后输入密码,此时域名呈现申请状态。提交申请后,原注册人通常会向您发送一封电子邮件,询问您是否同意转让。此时,您只需点击同意转移按钮,域名注册商就可以成功转移。
- 注册域名要了解几大点?新手有什么方式注册域名?
- 换新域名(重新来过)
- 深入了解飞行堡垒BIOS教程(掌握飞行堡垒BIOS设置技巧,保障电脑安全和性能)
- 前面这两个步骤都是在本机完成的。到这里还没有涉及真正的域名解析服务器,如果在本机中仍然无法完成域名的解析,就会真正请求域名服务器来解析这个域名了。
随便看看
- Copyright © 2025 Powered by SQL连接最全总结:提升你的数据库查询技能,云智核 滇ICP备2023006006号-28sitemap